 +7 (499) 704-50-30
+7 (499) 704-50-30 
Единая бизнес-система управления предприятием
Компания ЕВРАЗ с 2021 года внедряет управление производственными процессами на основе данных для снижения вариативности производства через реализацию методики «Бизнес-система ЕВРАЗ» (БСЕ, основанная на lean-технологиях). Методика направлена на улучшение процессов, начиная от базового уровня отдельных цеховых операций. В конечном итоге формируется управленческая отчетность от мастера до Президента, на едином источнике данных с возможностью фиксации отклонений, причин и реализованных контрмер. Измерение этих процессов – творческая, итерационная работа, что обуславливает сложность модели данных и требования к её гибкости. Ядром проекта является корпоративное хранилище данных, разработанное с использованием мета-компонентов BI.Qube.
О заказчике
ЕВРАЗ – одна из крупнейших металлургических компаний в мире с численностью персонала свыше 50 тысяч человек. Основные производственные активы расположены в России и включают полный цикл: от добычи сырья до выпуска готового проката. Этот цикл реализуется на 4 ключевых предприятиях компании. ЕВРАЗ ЗСМК является ведущим поставщиком рельсов в России и СНГ, а также одним из крупнейших производителей сортового проката. ЕВРАЗ НТМК лидирует по выпуску стальных двутавров и железнодорожных колёс. ЕВРАЗ КГОК играет ключевую роль в сырьевом обеспечении группы. ЕВРАЗ Ванадий Тула специализируется на производстве пентоксида ванадия для металлургии и смежных отраслей.
В ЕВРАЗе цифровая трансформация рассматривается как инструмент одного из ключевых элементов Бизнес-системы компании — совершенствования процессов. Цифровизация повышает безопасность сотрудников, эффективность бизнеса, ускоряет процессы и упрощает взаимодействие с клиентами. Важным направлением становится переход к управлению на основе данных на всех уровнях бизнеса: оператор технологического процесса получает помощь систем в обработке сигналов от датчиков оборудования в реальном времени; начальник цеха — инструменты для реагирования на отклонения, анализа проблем и их причин; топ-менеджмент — прозрачность процессов, выявление корреляций и более точное прогнозирование. Таким образом, цифровые инструменты становятся основой для более эффективного управления компанией, включая стратегический уровень.
Рассказывает Алексей Иванов, президент ЕВРАЗа. Для отраслевого портала о горнодобывающей промышленности «Союз горных инженеров»
Предпосылки и задачи
Единая система производственных показателей (ЕСПП) должна строиться на одних и тех же качественных и достоверных данных на каждом её уровне – от производственной линии до президента ЕВРАЗа. Был необходим ежедневный план/факт анализ выполнения ключевых производственных показателей, фиксация отклонений, причин, планируемых и реализованных контрмер. Требовалось обеспечить прозрачное использование этой информации от участка до центрального аппарата компании по семи направлениям:
- Производительность
- Цифровая трансформация
- ОТиПБ и экология
- Вовлечённость и повышение производственной эффективности
- Инвестиционная деятельность
- Персонал
- Финансовый результат
Для реализации проекта была привлечена команда BI.Qube, специализирующаяся на разработке корпоративных хранилищ данных, и уже имевшая опыт на проектах в ЕВРАЗе. Стояли задачи консолидировать производственные и непроизводственные данные из множества разнородных систем-источников, которых было свыше 30. Затем необходимо было построить единую модель и полноценный Data Lineage, связывающий данные с Бизнес-глоссарием и Дата-каталогом, обеспечить качество данных и формирование аналитических витрин с первичными и расчетными показателями:
- Показатели ЕВРАЗа, вариативность производственной программы
- Показатели Дивизиона, вариативность основных процессов
- Показатели цеха по ОТиПБ, вариативность KPI и факторы влияния
- Показатели участка, вариативность работы агрегатов на участке
На нижнем уровне – в пределах участков и цехов – данные используются в рамках Управления цифровой эффективностью (DPM) административной ячейкой (АЯ) для оперативного анализа и принятия решений в течение дня, а также ежедневных и еженедельных совещаний. На уровне дивизиона и центрального аппарата дашборды служат основой для ежемесячных совещаний по 7 ключевым направлениям. Таким образом, система обеспечивает сквозную аналитику – от агрегатов участка до управленческих показателей всей компании.
Проектное решение
Постановка задач и формирование центров компетенций
На старте проект охватывал 4 производственных предприятия, 11 производственных переделов, и первоначально была запланирована реализация свыше 9 000 показателей. При этом требовалось чтобы к 7 утра по местному времени была доступна вся отчётность за прошлый день, сами предприятия находятся в разных часовых поясах (Урал и Сибирь). Сроки горели, и требовался высокий темп реализации этого проекта. Каждый месяц должен был добавляться новый передел, а это порядка 300 новых показателей. Начав со стандартной линейной команды из 7 человек, масштаб и темпы проекта потребовали увеличить состав участников проекта до 25 человек, с формированием центров компетенций: аналитика (уточнение алгоритмов показателей с заказчиком), структура данных, загрузка данных, управление НСИ и мастер-данными (не плодить лишние справочники), технология агрегации для витрин (ClickHouse), компетенции по повышению качества SQL-кода (код-ревью для оптимизации, ускорения, предотвращения ошибок), CI/CD.
Формирование архитектуры
В процессе реализации проекта главным вызовом была сложность и неполнота модели данных. Требовалось поддерживать работу с разными видами показателей, отличающихся атрибутным составом, структурой и степенью детализации. При этом на старте проекта не существовало исчерпывающего описания модели данных, из 9 000 показателей были формализованы алгоритмы расчёта лишь примерно для 500. Было невозможно заранее предсказать, какие справочники, методы агрегации и трансформации должны быть поддержаны хранилищем данных. Модель была представлена абстракциями верхнего уровня, а конкретные алгоритмы расчета, представление на уровне системы-источника становились известны постепенно, по мере аналитической проработки. Это обусловило выбор в пользу методологии Data Vault, устойчивой к неполноте требований и изменчивости структуры хранения данных.
Архитектура системы сформирована из продуктов open source:
- PostgreSQL – объектно-реляционная СУБД с открытым исходным кодом. Аналог Microsoft SQL Server. Надёжна, подходит для OLTP-нагрузки и хранилищ объёмом до 1–2 ТБ
- S3 – объектное хранилище для файлов и резервных копий. Используется для выгрузки и хранения сырых данных, а также для обмена между системами
- Greenplum – распределённая аналитическая СУБД, построенная по архитектуре массово-параллельной обработки (MPP). Используется как хранилище данных от 2–3 ТБ. Совместима с PostgreSQL и поддерживает загрузку данных из S3
- ClickHouse – колоночная СУБД, оптимизированная для аналитических запросов в реальном времени. Используется для хранения событий и быстрой агрегации
- Airflow – оркестратор задач. Используется для автоматизации ETL-процессов и управления зависимостями между ними
- Kafka – распределённая платформа стриминга данных. Используется для передачи событий между системами в режиме реального времени
- Debezium – инструмент для Change Data Capture (CDC). Позволяет отслеживать изменения в базах данных и передавать их в Kafka
- React.js – JavaScript-библиотека для создания интерфейсов. Используется для разработки пользовательских панелей и визуализаций
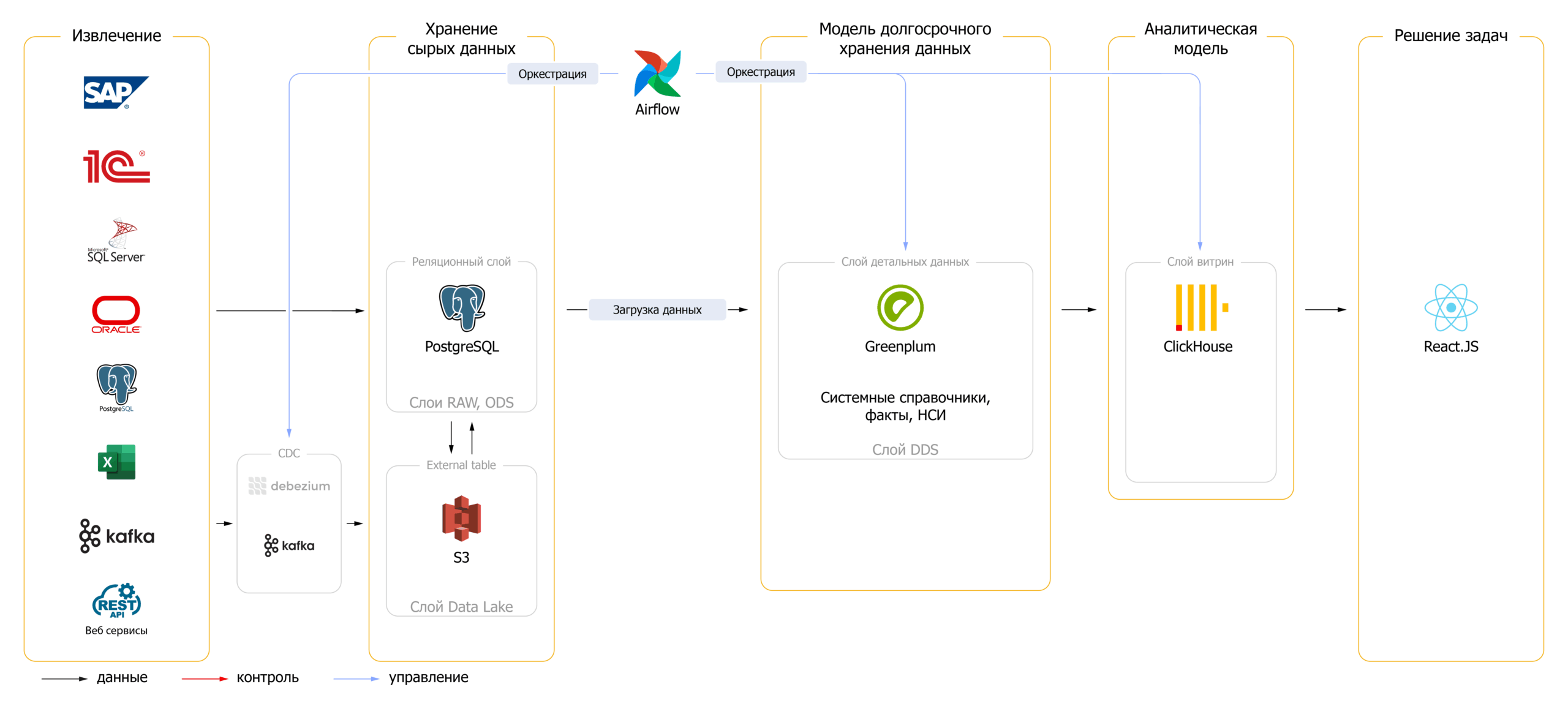
Использование open source-технологий позволило создать гибкую и масштабируемую архитектуру, но при этом потребовало глубокой технической экспертизы. В отличие от коммерческих решений, где многие функции реализованы «из коробки», работа с open source включает ручную настройку отказоустойчивости, производительности, поддержку версионности данных, управление мастер-записями и другие задачи, напрямую влияющие на стабильность и стоимость владения системой.
Для эффективного использования продуктов open source требовался инструмент, поддерживающий легкое расширение модели данных и функциональности работы с ними, желательно в визуальном интерфейсе с использованием концепции low-code/no-code. Например, что бы можно было легко добавлять новые справочники в модель данных, или поддержку новых нестандартных методов агрегации в обработку. Также нужно было управлять мастер-данными для устранения дублей. Чтобы эффективно реализовать сформированную архитектуру в адекватные сроки и бюджет, была необходима унификация подходов и автоматизация рутинных операций. Для этого был выбран фреймворк BI.Qube, который помогает выстроить стандартизированный процесс разработки поверх open source-стека. Разработчикам остаётся сфокусироваться только на бизнес-логике – всё остальное берёт на себя фреймворк.
Такой подход уменьшил трудозатраты и повысил качество кода, его производительность, снизил требования к квалификации разработчиков и облегчил поддержку системы. Благодаря использованию BI.Qube, удалось автоматизировать критически важные процессы работы с данными, минимизировать риски, и создать гибкую аналитическую платформу, не зависящую от зарубежных решений.
Состав платформы BI.Qube:
- MetaStaging – обеспечивает гибкое параметрическое автоматизированное формирование и выполнение задач транспортировки данных в DWH из различных СУБД, 1С, API, web-сервисов, непосредственно из локальных файлов так и из сервисов, как, например, Яндекс.Диск в форматах Excel, .csv и т.д.
- MetaVault отвечает за автоматизированное построение модели хранилища данных в методологии Data Vault 2.0
- MetaFact подготавливает оптимальную очередь выполнения процедур формирования фактов для оркестратора процессов, реализует гибкие сценарии, включая последовательно-параллельную сборку взаимозависимых объектов
- MetaCube выполняет автоматизированный перенос модели данных в витрины, гибкое секционирование, описание и формирование расчётных мер в нужных разрезах, автоматическое построение агрегатов
- MetaControl обеспечивает настройку правил контроля событий от технических, например, контроля за ETL-процессами до обеспечения Data Quality и любых бизнес-проверок
- MetaMasterData MDM-инструмент для работы с НСИ. Он выполняет задачи создания и обогащения данных, как вводимых в ручном режиме через веб-интерфейс, так и поступающих по альтернативным API
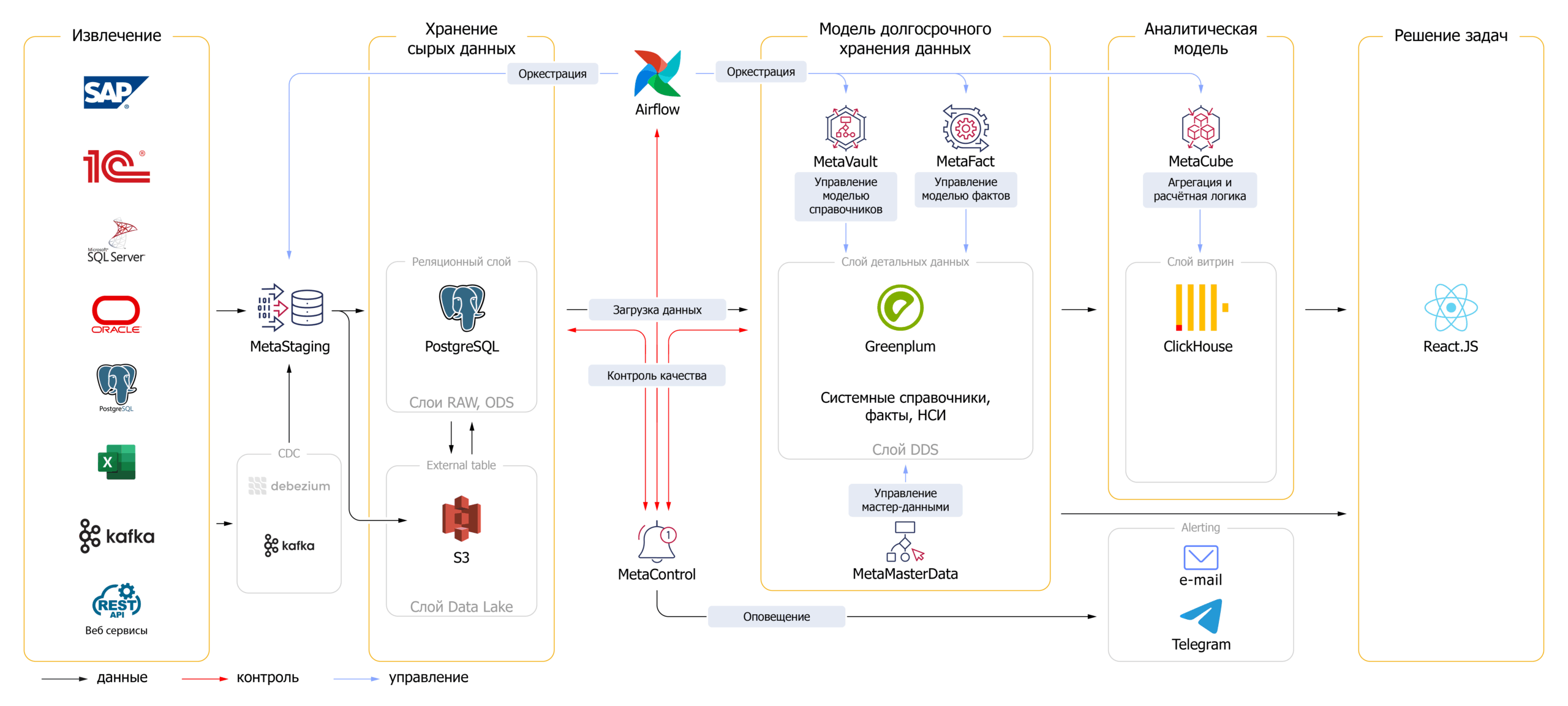
Был налажен унифицированный процесс разработки, в рамках которого ручному труду отводится лишь написание бизнес-логики расчёта показателей на SQL. Остальные функции выполняются автоматически за счёт использования метакомпонентов фреймворка BI.Qube. Это позволяет генерировать массу стандартизованного кода с поддержкой внесения изменений из визуального интерфейса, включая работу с такими объектами, как:
- Сущности MDM – объединение справочников с созданием «золотых» записей, на которые ссылаются сущности MDM
- Справочники Data Vault – создание, модификация структуры, актуализация данных и метаданных
- Базовые показатели – типовые утилитарные блоки работы с объектами СУБД
- Расчетные показатели, агрегаты – генерация DDL представлений в CliсkHouse
Использование BI.Qube позволило в несколько раз снизить трудоемкость по сравнению с ручной разработкой, что сэкономило порядка 50 миллионов рублей. Стандартизация и автоматизация также позволяют снизить стоимость дальнейшей поддержки и сопровождений.
Результаты внедрения
В данный момент система ЕВРАЗ ЕСПП находится в продуктивной эксплуатации и продолжает развиваться. свыше 400 активных пользователей на уровнях: CEO, Дивизионы (предприятия), Цеха, Производственные участки. При этом активно продолжается разработка новых показателей. К середине 2025 года реализовано порядка 3 000 показателей по 7 производственных переделам, описывающие следующие предметные области:
- Производственные процессы
- Производительность
- Цифровая трансформация
- Охрана труда и производственная безопасность
- Экология
- Вовлеченность
- Инвестиционная деятельность
- Персонал
- Финансовый результат
Хранилище данных стало единой точкой сведения информации для принятия управленческих решений с неограниченного гибкой моделью показателей.
ЕВРАЗ, подводя промежуточные итоги проекта на конференции Industrial Data 2024, сообщил что в процессе использования Единой системы производственных показателей уже достигнут экономический эффект от стабилизации производственных процессов свыше 1 миллиарда рублей. А общий экономический эффект проекта – более $200 млн. за 3,5 года реализации. После накопления нужного объема данных, будет возможно использование моделей искусственного интеллекта для прогнозирования, поиска причин отклонений факта от плана, и дальнейшей оптимизации производственных процессов.
Интерфейс системы
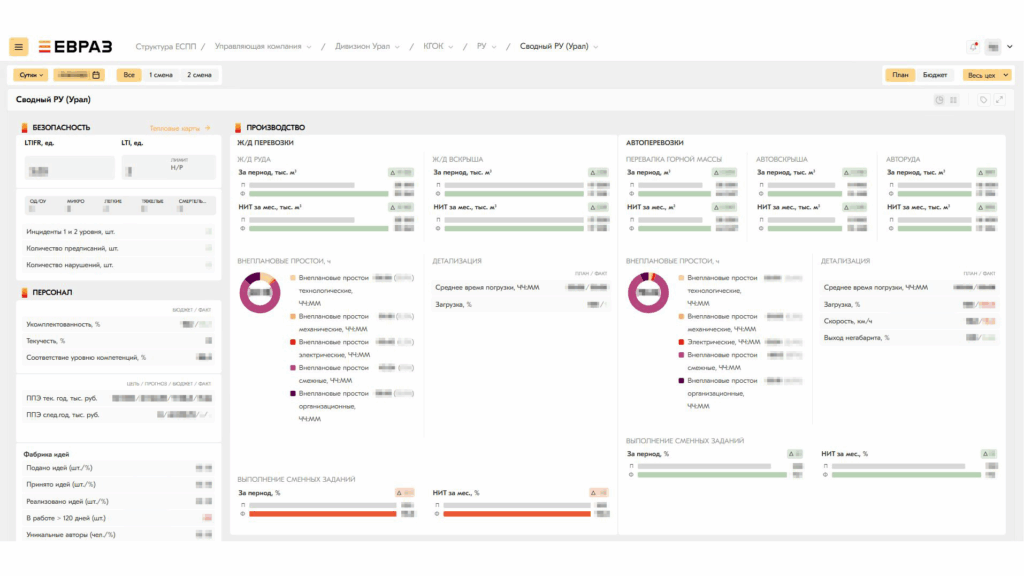
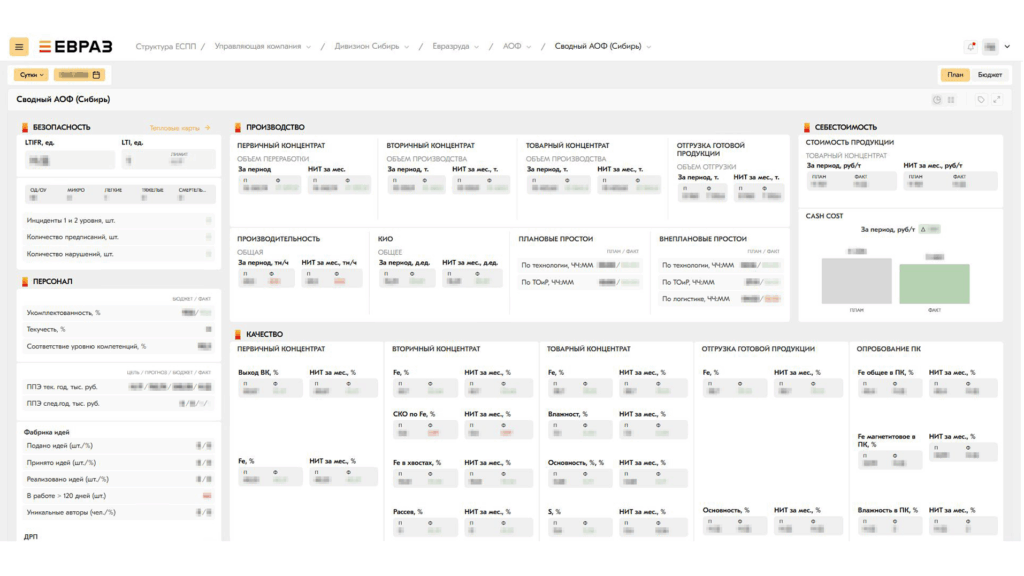
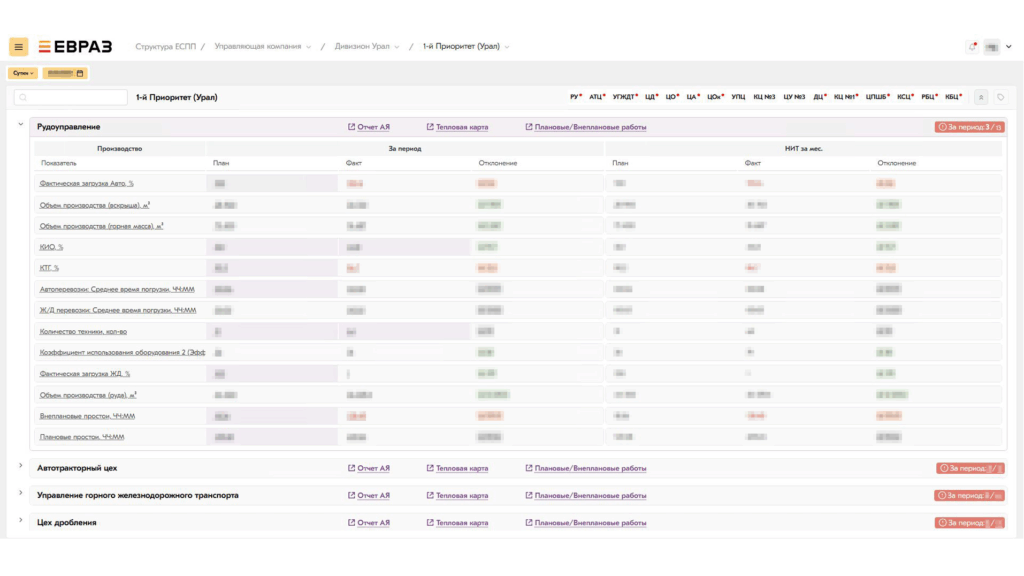
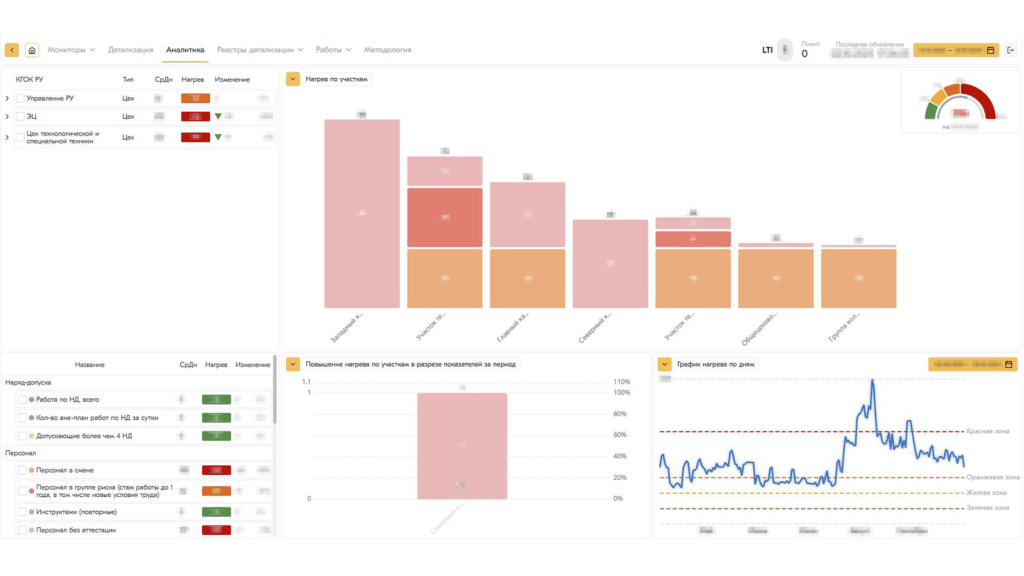
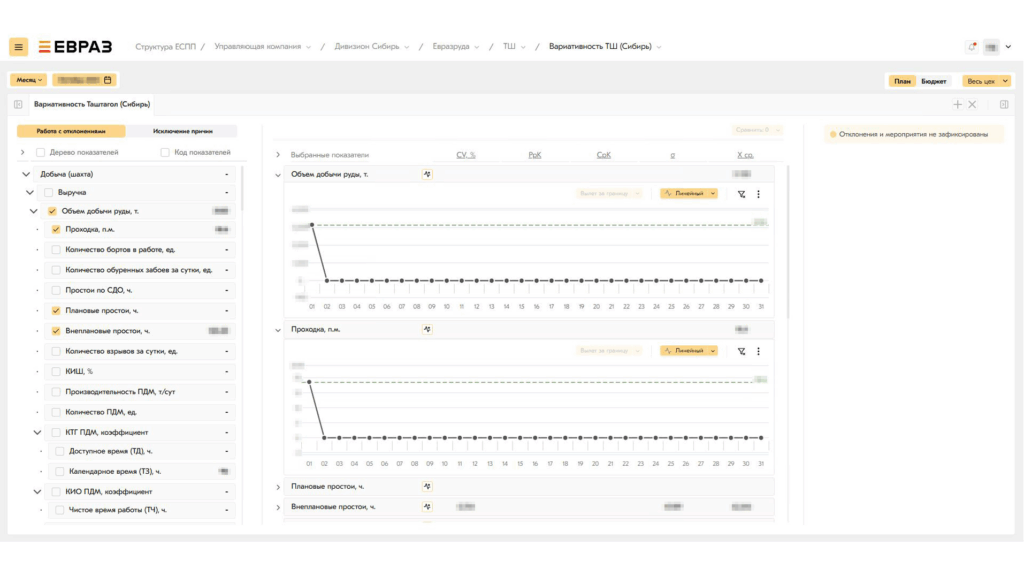
Преимущества
Применение правильных подходов и инструментов позволило сделать разработку более управляемой, что в свою очередь позволило:
- Сократить время на разработку проекта, за счет унификации и автоматизации
- Обеспечить высокий уровень качества полученного продукта
- Значительно упростить дальнейшее сопровождение проекта за счет автоматизации рутинных операций, генерации типового кода, перехода на более высокий уровень абстракции от написания кода к конфигурированию модели данных
- Снизить за счет унификации порог входа для новых разработчиков системы, гибко управлять размером команды разработки
- Тиражировать апробированный подход и архитектуру на новые проекты
Преимущества использования платформы BI.Qube
- Автоматизированная генерация SQL-кода (снижение ручного труда)
- Быстрое развертывание витрин в ClickHouse
- Стандартизация процессов ETL
- Сокращение сроков разработки и стоимости проекта: скорость разработки увеличилась в 2-3 раза по сравнению с ручным подходом, благодаря автоматизации

Проект реализован с использованием продукта BI.Qube командой интегратора IT Pro, которая отвечала за разработку хранилища, настройку репликации и ETL, создание витрин для высокопроизводительной аналитики. Экспертиза IT Pro помогла устранить проблемы с интеграцией данных из множества источников, задержками при работе с рассчитываемыми «на лету» данными и недостаточной производительностью аналитических запросов.


