+7 (499) 704-50-30
+7 (499) 704-50-30 Зачем ещё одна платформа для аналитики данных? Разбираемся с Tengri Data
Бизнес предъявляет высокие требования к работе с данными, объем которых растёт в геометрической прогрессии. Российские заказчики находятся в поиске высокопроизводительных платформ, простых в развертывании, не подверженных риску санкций, независимых от облачной инфраструктуры, со щадящими требованиями к железу. Для построения хранилищ данных нужна альтернатива как технологиям массовых параллельных вычислений (Greenplum), так и иностранным cloud-native платформам для работы с Big Data (Snowflake, Azure Synapse Analytics, BigQuery). Команда BI.Qube видит все эти возможности в новой российской платформе Tengri Data, разработанной Postgres Professional
Возможности Tengri Data
Tengri Data ориентирована на компании, которым необходимо выполнять ресурсоёмкие запросы и одновременно поддерживать работу множества аналитиков. Платформа решает задачи, традиционно распределённые между несколькими инструментами: построение хранилищ данных, аналитическая обработка, выполнение ML-задач, управление доступом и масштабирование. Она может использоваться как альтернатива: Spark, Exasol, Oracle, DB2, SAP Hana и др., особенно в тех случаях, когда импортные продукты недоступны по финансовым, юридическим или технологическим причинам.
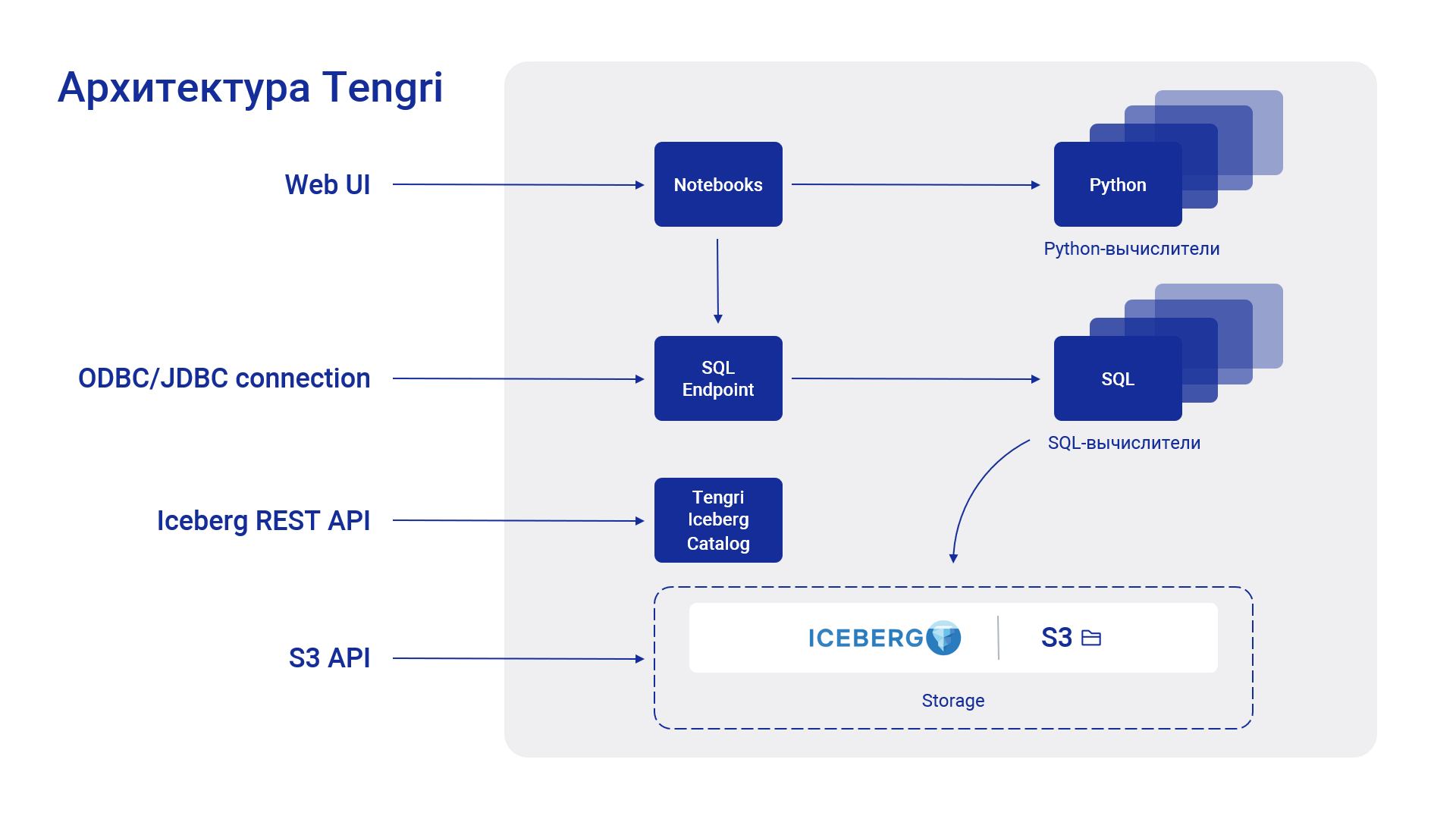
✅ Открытая архитектура хранения данных в формате Apache Iceberg в S3 дает возможность обращаться из других популярных аналитических систем с сохранением выданных на платформе прав. Использование колоночного формата хранения данных в файлах parquet и Apache Arrow в памяти повышает производительность за счёт снижения накладных расходов на сериализацию, десериализацию и обработку данных.
✅ Разделение вычислений и хранения данных, а также архитектура без использования координатора позволяет масштабироваться линейно относительно выделяемых ресурсов. В два раза больше железа = в два раза больше обработанных запросов за единицу времени. Tengri показывает лучшие результаты на том же оборудовании, где другие решения начинают «проседать», особенно в сценариях с большим числом параллельных пользователей.
✅ Для расчётов применяются надежно изолированные друг от друга SQL- и Python-вычислители, оптимизированные под современную архитектуру процессоров с использованием инструкций SIMD (Single Instruction, Multiple Data) для повышения производительности при выполнении параллельных операций. Применение современного железа в сочетании с компактным форматом хранения и передачи данных с быстрыми расчётами даёт возможность 99,9% запросов выполнять локально за приемлемое время, даже на петабайтных объемах хранилища данных.
✅ Работа с системой организована через изолированные сессии с удобными градациями фиксированного выделения ресурсов (ядер и памяти). Всё это позволяет сохранять отзывчивость системы даже во время выполнения ETL или при значительном росте нагрузки у аналитиков.
Практическое применение
Tengri Data – это современная аналитическая платформа, позволяющая получать результаты, недостижимые на других платформах, благодаря сочетанию современного железа и возможностей входящих в ее состав компонентов.
Tengri Data имеет полную поддержку ACID – благодаря этому платформу можно использовать как корпоративное хранилище данных, в отличие от ClickHouse.
Платформа сохраняет совместимость с PostgreSQL и стандартными аналитическими инструментами, что упрощает миграцию и снижает издержки на адаптацию. Поддержка Python и возможность локального выполнения аналитики делают её удобной для data science.
В то же время у Tengri Data есть и ограничения. В силу разделения вычислений и хранения данных платформа на текущем этапе развития не подходит для транзакционных нагрузок. Во-первых, ввиду существенных для OLTP задержек, во-вторых, из-за ориентации на пакетный ввод данных.
Команда BI.Qube предлагает создание хранилища в передовом подходе Data Lakehouse на платформе, которая не требует кропотливой настройки взаимосвязей множества компонентов. Фреймворк BI.Qube позволит упростить взаимодействие с платформой в сценариях очистки, подготовки модели, инкрементальной загрузки. Применение фреймворка BI.Qube поверх платформы Tengri Data автоматически формирует SQL на нижнем уровне, а также даёт средства моделирования и прозрачный Data Lineage.
Для компаний, которые не удовлетворены производительностью, зависимостью и поддержкой текущих систем, и ищут более эффективные подходы либо российские решения для обработки данных, Tengri Data является возможностью перешагнуть несколько стадий эволюции корпоративной аналитической платформы. Попробуйте платформу на реальных данных, особенно если в вашей команде уже есть опыт с PostgreSQL или Apache Iceberg.
С учётом готовности к работе «из коробки», фреймворка BI.Qube и опыта нашей команды – пилот позволит быстро получить результат и сформировать собственные компетенции. Оставьте заявку, будем рады помочь.